Hacking together a validator for Ren’Py translation file string identifiers.
Translation file IDs
Ren’Py has a built-in translation system where you just have to format files a specific way, write the translation string into the right block, and it will automatically magically insert the correct string for you. The magic block looks like this:
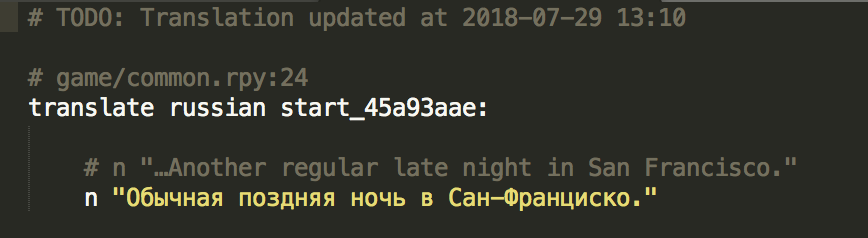
The key line to see is translate russian start_45a93aae:. The string ID start_45a93aae is how Ren’Py knows how to associate the translation text with its corresponding original version. If this ID changes, which it will if you so much as touch/edit the code file, then the translation will not work, and you’ll get a sudden mixture of languages like…

The only way to fix this is to find correct ID and update the translation file. This is a little bit more difficult than when we were manually extracting translation files since we don’t want to accidentally overwrite/change/do-something-bad to the translation. So, we build a verification tool by comparing both the line numbers of the original string (line 24 in the Russian language image) and the actual string (the commented block, # n "…Another regular late night in San Francisco.") with the string from the dialogue.tab file we extracted (see this post on translation files extraction to know what dialogue.tab is).
This is what our validator tool is going to spit out at us so that we know whether our lines and IDs are matching alright between the original dialogue and the translation file dialogue.
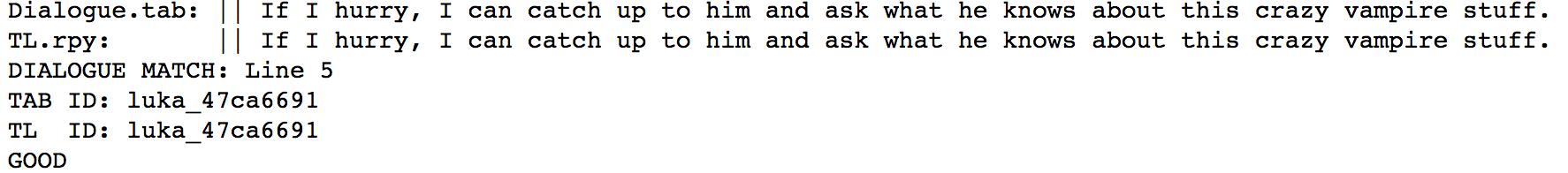
And the code…
# Import the dialogue.tab file with the original text and CORRECT IDENTIFIERS
import pandas as pd
import math
import re
re_df = pd.read_csv("dialogue.tab",sep='\t',skiprows=(0),header=(0))
# Open a translation file and read it
with open("game/tl/russian/common.rpy", "r", encoding="utf-8") as f:
common = f.readlines()
# Create a dictionary to hold the translation text. We want the format to be
# dictionary = {[line_number]:"dialogue string"}, where line number is the key and
# dialogue string is the value
common_tl_dict = dict()
common_tl_dict[count] = []
for line in common:
if line.startswith("# game/common.rpy"):
# Use magical regex to get the line number of a block
count = int(re.findall(re.compile("[0-9]+"),line.split(":")[-1])[0])
# Create a list() value to store the block of text. We want a list because
# we want to split a TL file into its tab delineated blocks
# And as we write this post, we realize we could probably have just run some sort
# of check for starting a line with spaces (\s). Oops.
common_tl_dict[count] = [line]
# If the line doesn't start with "# game/common.rpy", then we want to add it to the
# current line number's block of translated text.
if not line.startswith("# game/common.rpy"):
# A special case for common.rpy where translation strings for Ren'Py's Screens don't
# have an Identifier.
if line.startswith('translate russian strings:\n'):
break
# Add the new line to the current block
common_tl_dict[count].append(line)
# After we have the entire translation file read into a dictionary, we need to get rid
# of the generated comment block at the top of the file.
# #TODO: Translation updated at [date] is useless info.
common_tl_dict.pop(0, None)
# Grab all the text from the dialogue file that corresponds to the current file, since
# we don't want to worry about checking line 455 from common.rpy against line 455 from luka.rpy
# That would be bad. We'd get wrong string comparisons.
common_df = re_df.loc[re_df['Filename'] == 'game/common.rpy']
def line_id_compare(line_number, char_df, char_tl_dict):
'''
This function takes a line number and uses it as a key for two dictionaries
and compares their values.
::param line_number:: int
::param char_df:: dictionary of the text from dialogue.rpy
::param char_tl_dict:: dictionary of the translation file
'''
# These variables were declared outside the function and we want to be able to edit them
# here. They're declared outside because we want to increment them with each time this
# function is run, as it is run against a single line number at a time.
global num_lines_replaced
global unmatched
global unmatched_line_number
global replaced_line_number
# Find the correct row in the original dialogue file with the given line number
tab_row = char_df.loc[char_df["Line Number"] == line_number]
# Try to access dialogue. Sometimes there won't be any dialogue, and we don't want the
# function to die on us.
try:
tab_dl = tab_row["Dialogue"].to_string().split(" ")[1].strip('\\"')
except IndexError:
print("Index Error at line: {}".format(line_number))
print(tab_row["Dialogue"].to_string())
return
# Get the ID for the corresponding dialogue from dialogue.rpy
tab_id = tab_row["Identifier"].to_string().split(" ")[1]
# Get the text block associated with a specific line number in translation file
tl_dl = char_tl_dict[line_number]
# Get the ID from the translation text
tl_id = tl_dl[1].split()[2].split(":")[0]
# Get the dialogue from translation text
tl_orig_text = tl_dl[3]
# Delete weird special escaped characters like escaped quotes
tl_orig_text = re.findall(re.compile("\".+\""), tl_orig_text)[0].strip('\\"')
# Print the original dialogue.tab text and the translation dialogue text to see if they look the same.
# We don't want them to look the same and then the validator says they are different...
print("Dialogue.tab: || {}\nTL.rpy: || {}".format(tab_dl, tl_orig_text))
# Check if the two dialogue texts are the same. It would be bad to change the ID of two different
# texts to match because then we'd have a completely wrong translation...
if tab_dl == tl_orig_text:
print("DIALOGUE MATCH: Line {}".format(line_number))
print("TAB ID: {}\nTL ID: {}".format(tab_id, tl_id))
# Do both the IDs match? If yes, then we're all good to go, move on to the next string to compare.
if tab_id == tl_id:
print("GOOD")
else:
print("INCORRECT: Line{}".format(line_number))
print("REPLACING ID NOW...")
num_lines_replaced += 1
# We want to know which line IDs we are replacing so we can double check them later...
# Who trusts automatic programs.......
replaced_line_number.append(line_number)
# Replace the original translation ID with the new CORRECT ID
tl_dl[1] = "translate russian {}:\n".format(tab_id)
# Uh-oh, our dialogues don't match, and we have no idea what to do. Require human inspection.
# These are often due to weird quotation marks.
else:
print("DIALOGUE DOESN'T MATCH")
unmatched += 1
# Again, we want to know what the line number that errorred is...
unmatched_line_number.append(line_number)
print("num lines replaced: {}".format(num_lines_replaced))
print("num lines dialogue doesnt match: {}".format(unmatched))
num_lines_replaced = 0
unmatched = 0
unmatched_line_number = []
replaced_line_number = []
# Iterate through all the line numbers in the translation file and compare their IDs!
for key in common_tl_dict.keys():
line_id_compare(key, common_df, common_tl_dict)
print("unmatched line numbers: {}".format(unmatched_line_number))
print("replaced line number: {}".format(replaced_line_number))
# Write the corrected translation file back into a text file so that Ren'Py can access your
# automatically magically supposedly hopefully newly corrected translation file.
def write_new_tl_file(dic, filename):
ordered_entries = dic.values()
with open(filename, "w+", encoding="utf-8") as f:
for entry in ordered_entries:
for line in entry:
f.write(line)
# We are scared of overwriting the original file before we can double check any errors so
# write it to some new file.
write_new_tl_file(common_tl_dict, "common_updated.rpy")